11月27日晚间,DeepSeek在HuggingFace推出新型数学推理模型DeepSeekMath-V2,新模型采用可自我验证的训练框架。

该模型基于DeepSeek-V3.2-Exp-Base构建,通过LLM验证器自动审查生成的数学证明,并利用高难度样本持续优化模型性能。在2025年国际数学奥林匹克竞赛(IMO 2025)和2024年中国数学奥林匹克竞赛(CMO 2024)中均达到金牌水平,并在2024年普特南数学竞赛(Putnam 2024)中取得118/120(近乎满分)的优异成绩。
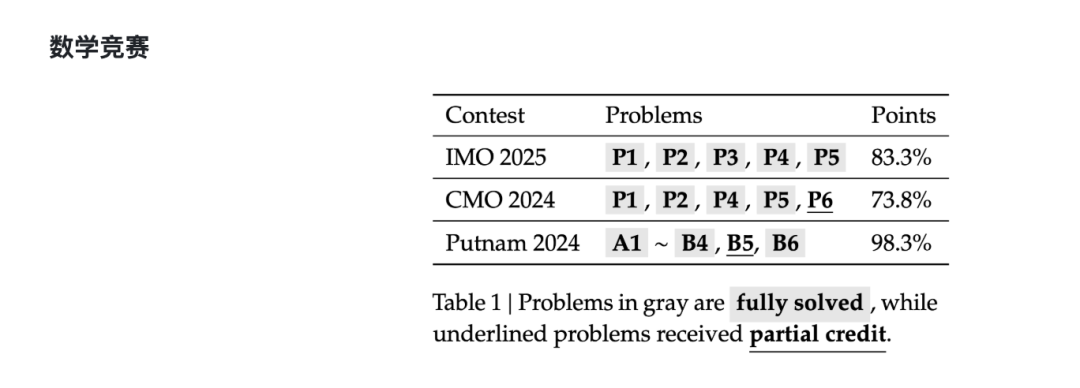
团队表示,该成果验证了自验证推理路径的可行性,为构建可靠数学智能系统提供新方向。新模型代码与权重已开源,发布于Hugging Face及GitHub平台。
DeepSeek团队认为,大型语言模型在数学推理方面取得了显著进展。然而,追求最终答案准确性并不能解决一个关键问题:即正确的答案并不能保证正确的推理。许多数学任务如定理证明,需要严格的逐步推导,而不是数值答案。为了突破深度推理的极限,团队认为有必要验证数学推理的全面性和严谨性。
DeepSeekMath-V2的核心架构构建了一个自驱动的验证-生成闭环:将一个LLM作为“审稿人”担任证明验证器,另一个LLM作为“作者”负责证明生成,两者通过强化学习机制相互协作,并引入“元验证”层来有效抑制模型幻觉。

DeepSeek团队在论文中提及,在自主构建的91个CNML级别问题测试中,DeepSeekMath-V2展现出卓越的数学推理能力。在代数、几何、数论、组合学和不等式等所有类别中均超越了GPT-5-Thinking-High和Gemini 2.5-Pro的表现。

在IMO-ProofBench基准测试中,该模型同样表现优异:在基础集上,其人工评估结果优于DeepMind的DeepThink(IMO金牌水平);在更具挑战性的高级集上,模型保持了强劲的竞争力,同时显著超越了所有其他基准模型。

DeepSeek团队表示,尽管仍有大量工作有待完成,但这些成果表明,自我验证的数学推理是一条可行的研究方向,这或许有助于开发功能更为强大的数学人工智能系统。
(文章来源:上海证券报)




