在6月中旬获得500亿融资后仅十几天,6月27日,DeepSeek团队联合北京大学发布论文《DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation》。
这不是一次模型版本的迭代,而是在原有DeepSeek-V4-Pro和DeepSeek-V4-Flash基础上增加了一个推测解码模块,重点在于工程落地层面的优化。
随DSpark一同开源的DeepSpec,是一个用于训练和评估推测解码草稿模型的全栈代码库,包含数据准备工具、草稿模型实现、训练代码和评估脚本,支持MIT许可。目前DeepSpec已内置DSpark、DFlash和Eagle3三种实现。
值得注意的是,DeepSeek创始人梁文锋位列论文作者名单。在完成首轮融资的当下,创始人依然亲自参与技术论文撰写,这在AI行业并不多见。

实测数据验证:同等吞吐下,V4-Flash提速60%-85%,V4-Pro 提升 57%-78%
不同于仅停留在实验室的算法优化,DSpark 已完成真实用户流量落地验证。该框架全面部署于 DeepSeek-V4-Flash、V4-Pro 线上服务,替代此前 MTP-1 生产基线。在同等系统总吞吐规模下,V4-Flash 单用户生成速度提升 60%-85%,V4-Pro 提升 57%-78%。
除了DeepSeek自家的大模型,DSpark也已经部署到了阿里旗下的Qwen3-4B、8B、14B,以及Gemma4-12B。三大评测领域分别是:数学推理、代码生成、日常对话。
DSpark兼容 Qwen、Gemma 等国内外主流基座,同时配套 DeepSpec 仓库、模型权重全部开源。这意味着,对于缺乏底层算法团队的中小企业、ToB 服务商,无需投入巨额研发即可复用成熟推理优化方案,大幅降低大模型私有化部署、线上服务的落地门槛,智能体、工业代码、金融舆情等场景规模化落地速度有望加快。
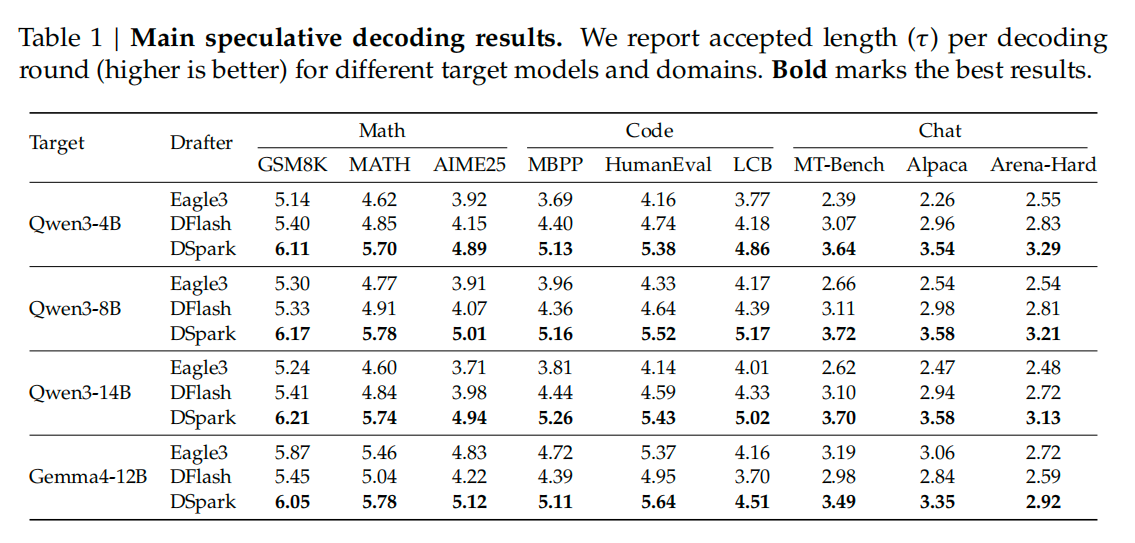
论文数据显示,DSpark 在全部目标模型、全部评测领域下,稳定超越自回归基线 Eagle3 与并行基线 DFlash。以 Qwen3-4B/8B/14B 为例,宏平均接受长度相对 Eagle3 提升 30.9%、26.7%、30.0%;相对 DFlash 提升 16.3%、18.4%、18.3%。这一优势具备跨模型的泛化能力,在Gemma4-12B目标模型上同样取得了一致的性能增益。
除整体提升外,论文实验数据还揭示了显著的领域差异效应::结构化任务(如数学推理、代码生成)的可接受长度天然更高(例如Qwen3-4B在数学任务上平均为5.57,代码任务为5.12),而开放式对话场景则明显偏低(仅3.49)。
论文也指出当前方案存在局限:对于本身可预测性极低、接受率偏低的复杂查询,这部分前置草稿算力无法回收。未来的优化方向可在草稿模型内部引入难度感知的早退出机制,使此类请求能够跳过完整块生成流程。
不拼参数拼速度:DSpark的两项技术突破
大语言模型采用自回归方式生成文本——每生成一个新token都需要一次完整前向传播,推理延迟随输出长度线性增长。推测解码(Speculative Decoding)是行业公认的解决路径:用一个轻量级草稿模型快速生成候选token,再由大模型批量验证。
但现有方案各有短板。
自回归草稿模型(如Eagle3)逐token串行生成,依赖关系建模能力强、接受率高,但草稿耗时随候选块长线性增长,只能使用短块、浅层网络。
为打破串行瓶颈,并行草稿模型成为更优方案:所有草稿位置仅需单次前向传播即可生成,草稿耗时几乎不受块长影响。但想要充分发挥长并行草稿块的潜力,仍存在两大核心瓶颈:
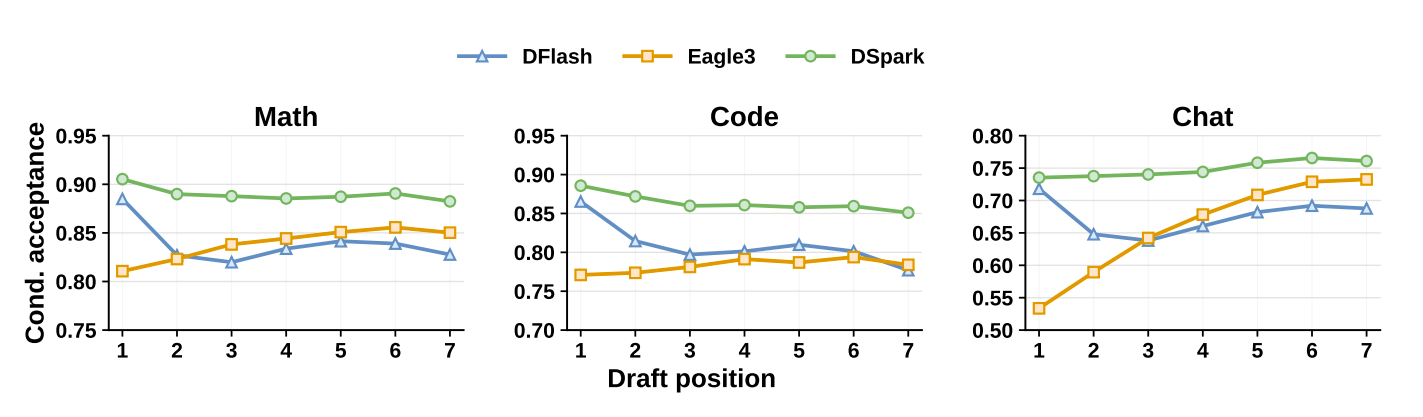
生成质量瓶颈:并行草稿模型独立预测每个位置,无法建模块内 token 依赖,会出现多模态冲突问题,序列后半段 token 接受率快速衰减;
系统效率瓶颈:最优验证长度难以确定。并行生成虽能产出长草稿块,但不加区分地验证全部 token 会降低系统吞吐,高并发场景下问题尤为突出。
DSpark针对这两大瓶颈提出两项互补机制。
半自回归生成架构:保留并行主干的高吞吐优势,同时加入轻量级串行模块,逐token注入前缀依赖信息。该模块提供两种实现——仅依赖前一个token的马尔可夫头,以及通过循环状态累积完整前缀信息的RNN头。实验表明,两层Transformer深度的DSpark即可在所有测试领域超过五层DFlash的接受长度。
置信度调度验证机制:引入置信度头评估每个token在给定前缀下的“存活概率”。硬件感知前缀调度器根据实时引擎吞吐量动态决定最优验证长度,优先将算力分配给预期回报最高的token。论文发现原始置信头存在置信度过高问题,团队设计了“时序温度缩放”后验校准方案予以修正。
DeepSeek 在完成大额融资后并未单纯追求参数扩容,而是关注落地效率,击中产业真实痛点。在生成式AI从实验室走向商业化的周期里,“更快、更省算力”正在取代单纯的模型跑分,成为厂商竞争力的关键指标。

(文章来源:财联社)




