今日,华为发布半导体“韬(τ)定律”概念。
2026国际电路与系统研讨会上,华为公司董事、半导体业务部总裁何庭波在题为《半导体新路径探索与实践》的主旨演讲中,正式发表了这一定律。这是中国在全球半导体领域首次提出指导产业发展的新原则。预计到2031年,基于该定律的高端芯片晶体管密度将达到1.4纳米制程的同等水平。
之后,由何庭波署名的论文《A Time Scaling Theory for Multi-Layer Electronic Systems》已提交至中国科学院科技论文预发布平台,论文详细介绍了“韬(τ)定律”。
“韬(τ)定律”是自登纳德缩放定律以来,首个在整个计算栈建立统一优化目标的缩放原理。该定律不再将晶体管面积,而是将“时间”本身作为技术进步的核心衡量指标,采用单一特征时间常数τ作为统一优化目标,覆盖从单个开关晶体管到数据中心工作负载、跨越十二个数量级的整个计算体系。
论文展示了两个量产级别的验证案例:在移动SoC方面,逻辑折叠技术在相同器件节点下,实现了晶体管密度55%的阶跃式提升,以及41%的能效增益;在AI系统方面,由具备内存语义统一总线架构、近封装 Hi-ONE光学I/O,以及edge-to-surface 3D折叠技术共同构成的协同设计技术栈,预计到2035年将实现超过100倍的硬件集成度增长。
这篇论文不仅透露了华为未来十年的部分芯片发展路线,也指明了多个技术方向。
混合键合与TSV
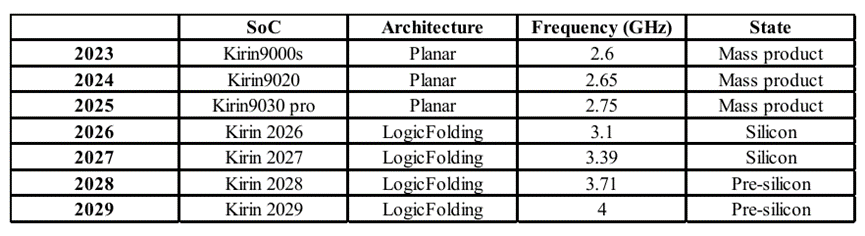
未来十年,逻辑折叠技术预计将从局部关键路径折叠,演进为全面、多层级的折叠架构——即在单个封装内集成三层、四层甚至更多有源层堆叠。
这一演进将有赖于两大技术支撑:一是低温混合键合技术,有助于放宽各堆叠层之间的热预算要求;二是TSV(硅通孔)落点下移,从顶层金属层下移至M6金属层,此举可释放超过30%高层布线资源。
2026-2035 年,晶体管密度预计将提升至接近甚至超过每平方毫米4亿个晶体管(400 MTr/mm²)。同时,逻辑折叠技术还将显著提升麒麟芯片CPU核心频率,并为迈向4 GHz甚至更高频率铺平道路。这一技术路线图不仅在技术上可行,在成本层面也具备经济可行性。
3D堆叠
论文指出,3D堆叠的发展将是必然。
“扇出困境”将导致2.5D扇出型封装扩展能力受阻,而3D堆叠则将解决这一困境,封装将变成垂直集成堆栈,内存、互连网络、供电与逻辑电路都能同步扩展。
其也给出了较为明确的时间线:大约在2030年以前,昇腾超节点产品线(包括2025年的昇腾910C、2026年的昇腾950,以及后续的昇腾990)仍将依赖一系列成熟技术组合:Chiplet、2.5D扇出,以及基于微凸点(micro-bump)和标准间距混合键合的3D堆叠。
2030年左右,昇腾990将首次把逻辑折叠技术引入AI加速器领域;自那之后,3D堆叠将成为2035年前α(性能扩展系数)的主要承载方式。沿着这一技术路径,到2035年,硬件集成度预计将提升超过100倍,而τ(延迟/时间常数)的下降将分布在整个堆栈的各个层级中,而不再仅仅集中于器件层面。
从铜互连到光互联
论文提出,在每颗AI芯片400 Gb/s的带宽水平下,铜缆互连仍然是成熟、可靠且易于实现的方案。但当单芯片带宽提升至数 Tb/s 级别时,铜互连在物理层面将难以为继。
由此,华为半导体开发了高密度光互连节点引擎(High-density Optical-interconnect-Node Engine,Hi-ONE)——一种近封装光引擎。该方案可为每个模块提供8 Tb/s带宽,并通过单条光链路实现与AI芯片UB带宽相匹配的传输能力。它将SerDes(电串行器)所需传输距离从约100厘米缩短至约5厘米,并将传输距离从不足1米扩展至100米,从而使面向分布式、吉瓦级数据中心的高密度互连在物理上真正具备可实现性。
值得注意的是,何庭波在论文最后直言,未来资金应当重视τ,而不是仅仅追随制程工艺节点——竞争优势不再单纯依赖最先进光刻工艺,从战略地位来说,封装技术、内存带宽和互联架构设计如今也和先进制程节点同样重要。

(文章来源:财联社)




