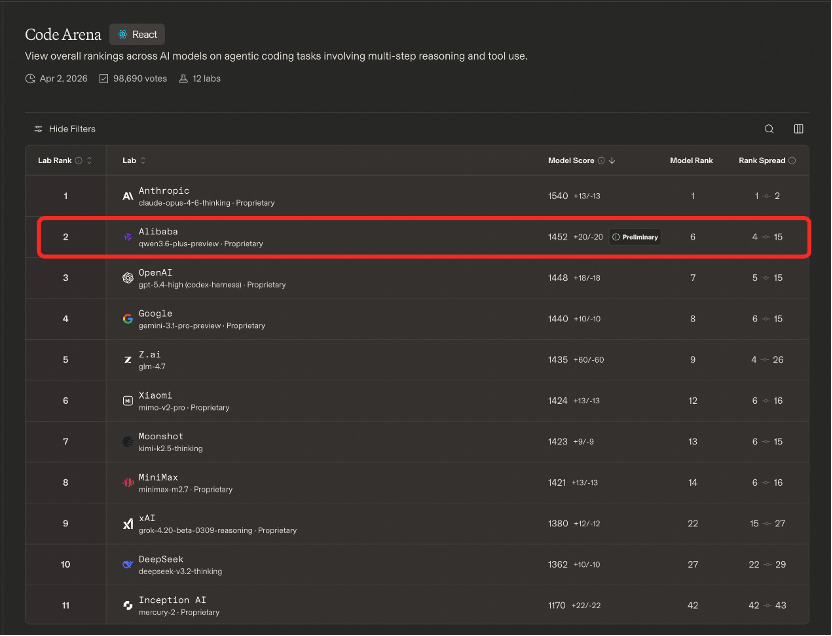
4月3日,全球知名大模型盲测榜单LMArena旗下聚焦AI编程能力的Code Arena公布新一期排名,阿里巴巴最新一代大语言模型Qwen3.6-Plus登上全球榜单第二,超越OpenAI、Google、xAI等国际巨头,成为该榜单上排名最高的中国大模型。
企业供图
LMArena作为当前AI领域最具公信力的大模型盲测平台之一,采用真实用户盲测、实时对抗排名的机制,因此也被视为是AI领域最公正权威的全球大模型性能榜单。随着Agent时代的到来,编程能力成为衡量模型综合实力的关键,该榜单备受关注。
本次Qwen3.6-Plus斩获第二的React专项榜单是目前AI Coding领域最前沿、挑战性最高的一个技术方向,旨在考察大模型在真实复杂Web开发场景下的自主编码能力。与传统的单一代码补全测试不同,该榜单要求模型具备完整的工程思维和端到端开发能力,能够在无人辅助的情况下独立完成从项目初始化、代码编写到调试运行的全流程。
Qwen3.6-Plus是阿里巴巴于4月2日最新发布的新一代大语言模型,拥有原生多模态理解、推理能力,并在代码生成与Agent能力上表现突出。在多项权威编程评测中,千问3.6均超越参数量是其两倍乃至三倍的GLM-5、Kimi-K2.5等模型,以更少的参数实现了更强的性能,成为当前国产模型中编程能力的标杆。
榜单数据显示,千问3.6得分仅次于Anthropic旗下的Claude-Opus-4.6-Thinking(1540分),以4分优势领先OpenAI最新发布的GPT-5.0-High(1448分),并以12分差距超越Google的Gemini 3.1 Pro Preview(1440分)。这意味着,在最具挑战性的AI Coding和Agent任务中,千问3.6展现出与全球顶级大模型比肩甚至更优的代码生成与工程化能力。此外,在全面评估AI编程能力的CodeArena榜单中,Qwen3.6-Plus同样位居国产模型之首。凭借这一成绩,阿里巴巴在全球AI实验室排名中升至第四,仅次于Anthropic、OpenAI和Google。
Qwen3.6-Plus是阿里千问3.6推出的第一款模型,后续千问3.6系列还将开源其他尺寸模型,性能更强的旗舰模型Qwen3.6-Max也将于近期发布。
(文章来源:证券日报)




