谷歌推出压缩算法TurboQuant 宣称实现约6倍内存节省
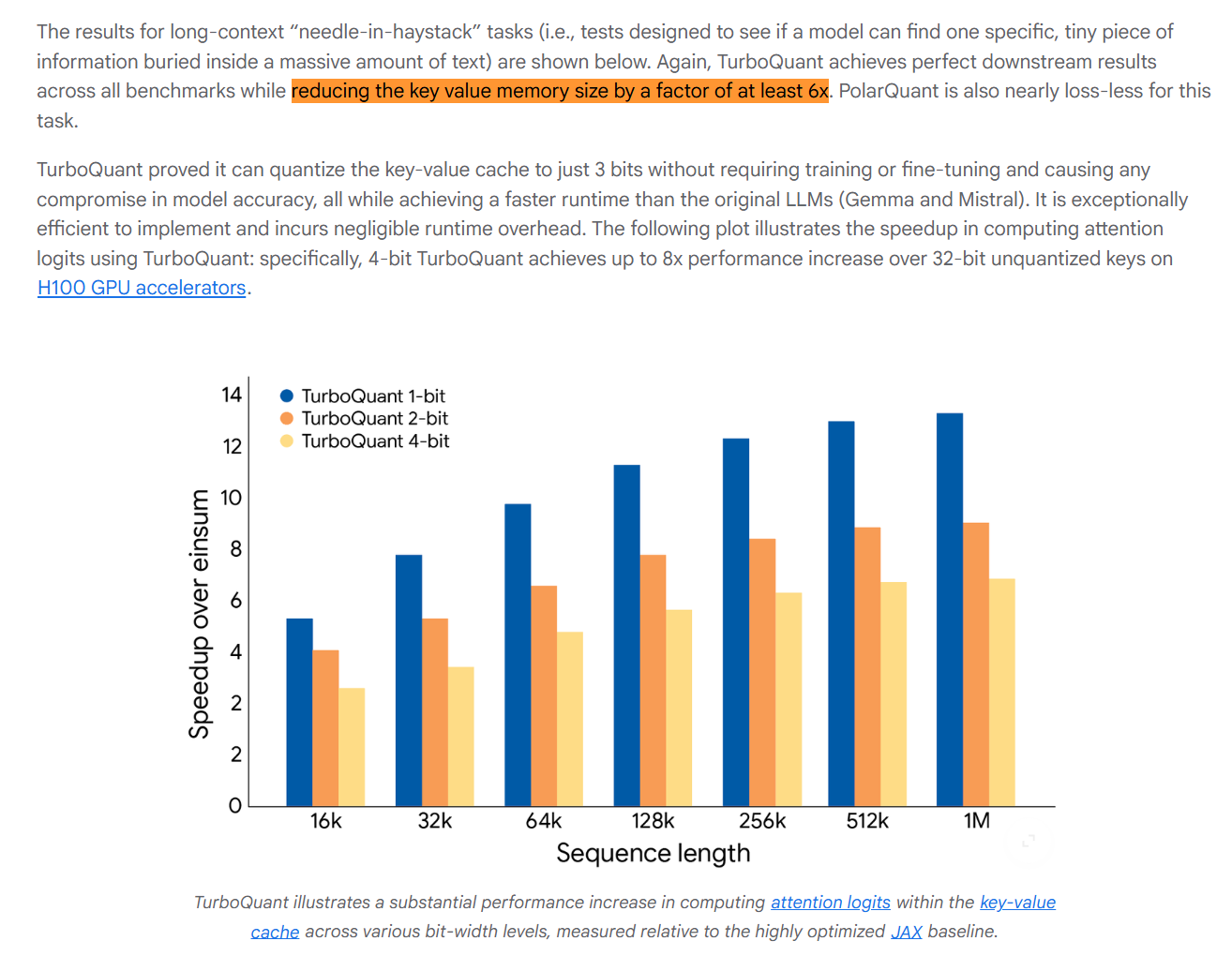
谷歌近日推出了一种可能降低人工智能系统内存需求的压缩算法TurboQuant。根据谷歌介绍,TurboQuant压缩技术旨在降低大语言模型和向量搜索引擎的内存占用。该算法主要针对AI系统中用于存储高频访问信息的键值缓存(key-value cache)瓶颈问题。随着上下文窗口变大,这些缓存正成为主要的内存瓶颈。TurboQuant可在无需重新训练或微调模型的情况下,将键值缓存压缩至3bit精度,同时基本保持模型准确率不受影响。对包括Gemma、Mistral等开源模型的测试显示,该技术可实现约6倍的键值缓存内存压缩效果。此外,在英伟达H100加速器上的测试结果显示,与未量化的键向量相比,该算法最高可实现约8倍性能提升。研究人员也表示,这项技术的应用不局限于AI模型,还包括支撑大规模搜索引擎的向量检索能力。谷歌计划于4月的国际学习表征会议(ICLR 2026)上展示TurboQuant技术。
(文章来源:财联社)




