近年来,AI大模型的编程能力突飞猛进,各大AI厂商在编程基准测试上你追我赶,不断刷新纪录。这让不少程序员开始担忧:AI是不是很快就要抢走我们的饭碗了?
然而,中山大学与阿里巴巴联合发布的一项最新研究给程序员们吃下了一颗“定心丸”。
3月4日,两家机构联合发布了一项评测结果。这项测试名为“SWE-CI:通过持续集成评估智能体维护代码库的能力”(SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration),首次对包括Anthropic、OpenAI、Kimi和DeepSeek等8家主流厂商的18款AI大模型的长期代码维护能力进行了严苛的系统性评估测试。
测试包含100项任务,总Token消耗超100亿。结果显示,Claude Opus系列综合表现领跑。
在控制性能退化方面,千问、DeepSeek、MiniMax、Kimi和豆包等大多数AI大模型的表现明显不佳。也就是说,AI在长期代码维护过程中,可能将代码“越改越糟”。
长期以来,AI编程能力的主流评测基准的共同特点是快照式评测,以“单次接收需求、一次性输出解决方案”为核心。
然而,这种评估方式仅检验大模型是否能写出功能正确的代码,无法反映真实软件开发中持续迭代、长期维护的核心需求。
在现实中,成熟的软件很少是一蹴而就的,而是长期维护的结果。雷曼定律表明,软件质量会随着维护的进行而自然下降。而维护工作占软件生命周期总成本的60%到80%。
为评估AI在长期代码维护中的表现,中山大学与阿里巴巴团队联合推出了SWECI评测基准。这是全球首个专门评估AI智能体在长期代码维护表现的评测系统,它不再满足于考察AI编程的“一次性正确”,而是评估AI是否像真正的软件工程师一样,在数月甚至数年的开发过程中持续保持代码质量。
SWECI基准测试的构建经过四层严格筛选,最终形成高质量评测集。
研究团队先从GitHub全网的Python代码库中筛选出维护三年以上、星标超500、包含依赖文件和完整单元测试套件,以及采用MIT/Apache2.0等宽松协议的4923个代码库;再提取依赖稳定、代码修改量超1000行的提交对,得到8311个候选样本;通过自动构建Docker环境与自修复依赖机制,保留1458组可运行候选对;最后经测试启动校验、通过率差异筛选、时间跨度与提交量排序,确定100项最终任务。
研究团队精心构建的100项任务中,每项任务都对应着真实世界中一个软件项目的完整进化历程。这些项目平均跨越233天的开发时间,包含71次连续的代码提交记录。团队还设计了一个精巧的“架构师-程序员”双智能体协作机制。设计的灵感来自真实软件团队中常见的分工模式:架构师负责分析需求和制定技术方案,程序员负责具体的代码开发。
为适配长期迭代评测,SWECI提出了“归一化变化”与“EvoScore(进化得分)”两大核心指标。
“归一化变化”以测试用例通过数为基础,将代码状态映射到[-1,1]区间,正向表示功能提升,负向表示出现功能退化。
EvoScore更侧重衡量AI大模型在未来修改任务中的表现。
研究团队对8家公司——月之暗面、Anthropic、智谱、千问、MiniMax、DeepSeek、OpenAI和豆包——的18个主流AI大模型进行了系统性测试,累计消耗了超过100亿Token的测试数据。这一实验规模在AI编程评估领域堪称史无前例。
研究结果显示,从时间维度来看,AI大模型在代码维护能力上的进化呈现出明显的加速曲线。
从下图可以发现,同一厂商的大模型新版本普遍稳定高于前一代,且2026年后的跃升幅度显著扩大,EvoScore更高。这表明,当前大模型的代码能力正从静态缺陷修复,快速向持续、长期的代码维护演进。
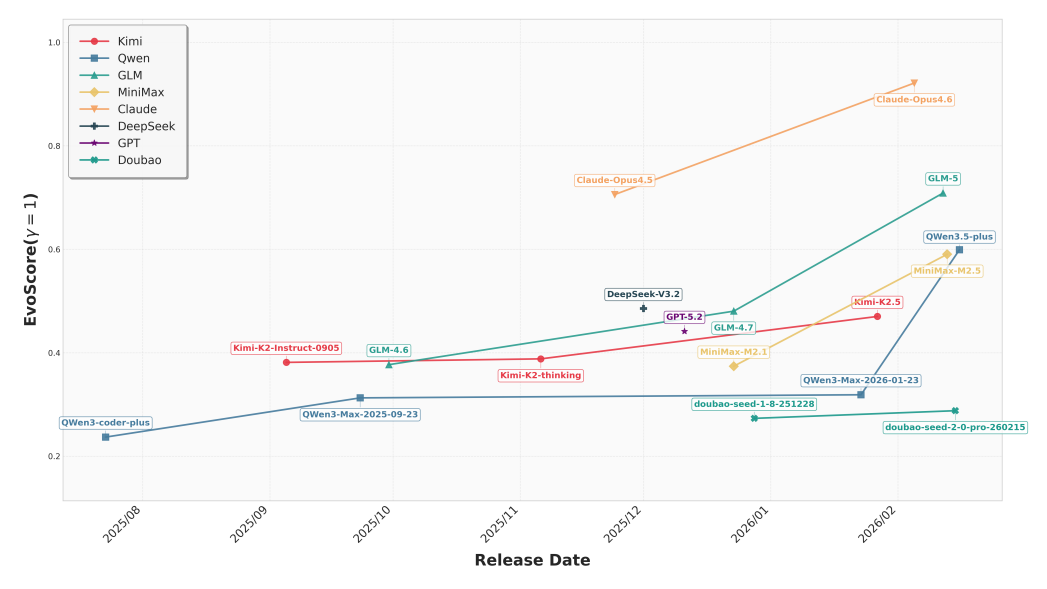
8家厂商的主流大模型在SWECI测试中的EvoScore变化情况。图片来源:论文截图
在所有参评大模型中,Claude Opus系列表现最为突出,从Claude-opus-4.5到Claude-opus-4.6,其EvoScore跃升至约0.9的高位,明显拉开了与所有竞争对手的差距。
中国的AI大模型中,智谱GLM系列进步显著,成为第二梯队中最具竞争力的选手。紧随其后的是Qwen和MiniMax,整体趋势向好。而Kimi和豆包虽有提升,但缺乏突破。
研究还发现,不同厂商在大模型训练策略上偏好存在明显分化。
具体而言,MiniMax、DeepSeek以及OpenAI的GPT系列大模型更偏好长期效益,显示出其在长期代码维护任务中的优势。这意味着,这类大模型在生成代码时,更倾向于采用有利于长期演进与稳定性的策略,而非追求短期修复的最优解。
相比之下,Kimi与智谱GLM系列更偏向于短期见效的优化路径。
而千问、豆包以及Claude系列大模型则呈现出另一种特征:其训练策略在短期效果与长期维护之间取得了一定平衡。
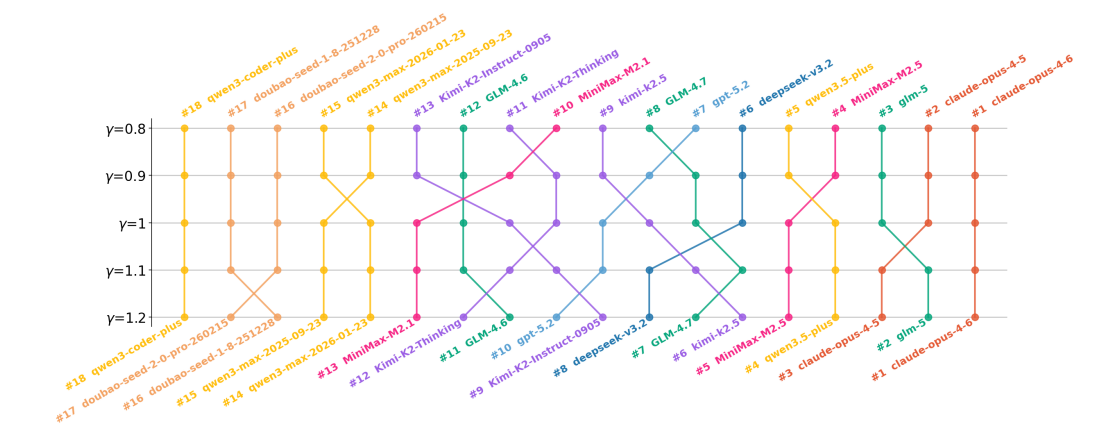
随着权重参数γ的变化,各个大模型的排名也随之发生显著调整。当γ>1时,大模型排名越高,其代码库维护能力越强。图片来源:论文截图
另外,研究还有一项关键发现:在长期代码维护中,所有大模型在有效控制性能退化(Regression)方面都表现不佳。
性能退化是衡量软件质量稳定性的核心指标。如果某个单元测试在代码更新前已经通过,而更新后失败了,则判定该变更触发了性能退化。一旦出现性能退化,不仅会直接影响用户体验,在长期维护过程中,随着修改次数累积,还可能导致系统质量系统性退化。
研究团队测量了“零退化率”——即在整个维护过程中完全没有破坏原有功能的任务比例。零退化率越高,维护的系统越稳定。
研究结果表明,在所有参与测试的18个大模型中,只有Anthropic的Claude Opus大模型保持了50%以上的零退化率,大多数大模型的零退化率都低于25%。
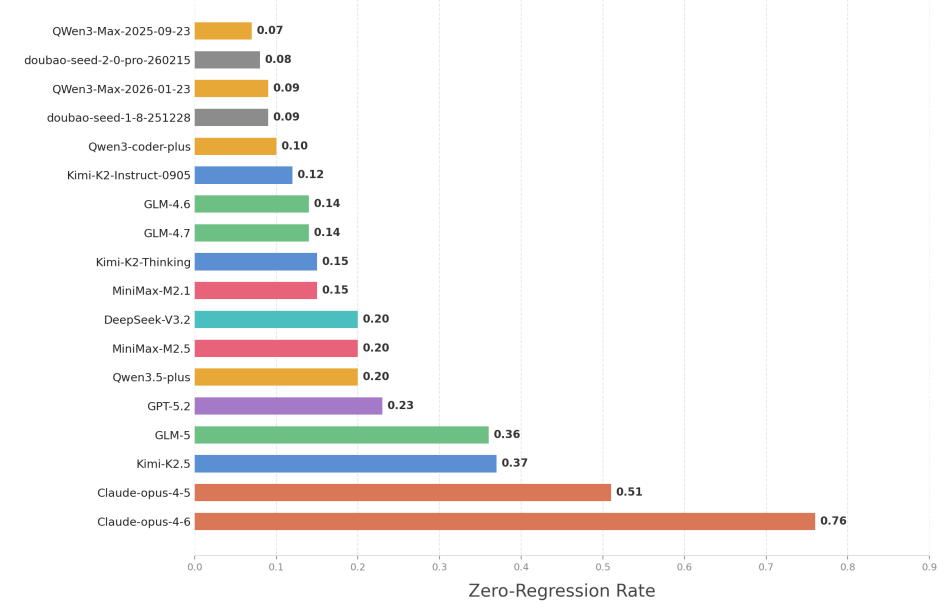
18个大模型的零退化率(从低到高排序)。图片来源:论文截图
具体而言,Claude-opus-4.6以76%的零退化率遥遥领先。这意味着在绝大多数测试场景中,其性能能够保持稳定。Claude-opus-4.5以51%位列第二。相比之下,Kimi-K2.5(37%)与GLM-5(36%)表现接近,构成第二梯队,虽具备一定稳定性,但与头部大模型仍存在显著差距。
包括GPT-5.2、Qwen3.5-plus、MiniMax-M2.5和DeepSeek-V3.2在内的其余14个AI大模型的零退化率都在25%以下,这意味着在长期代码维护过程中,大模型在超过75%的任务中会破坏原本正常的代码功能,引发性能退化问题。
但从版本迭代的角度看,头部厂商的AI大模型正快速进步。例如,Claude-opus系列的“零退化率”从4.5版本的51%提升至4.6版本的76%,智谱GLM系列从GLM-4.6和GLM-4.7的14%跃升至GLM-5的36%。
但即便如此,绝大多数大模型仍难以在长期代码维护中杜绝性能退化问题,距离可靠的自动化长期开发仍有明显差距。
SWECI基准测试结果的发布,让行业意识到,“写代码”和“维护代码”是两种截然不同的能力。对于大模型厂商而言,持续优化可维护性、性能退化控制、架构设计能力,或许将是赢得下半场竞争的关键。
(文章来源:每日经济新闻)




