类似手机时代厂商发布新机需要“跑个分”,如今大模型厂商发布新产品后也会通过基准测试(Benchmark)跑分对比,但随着基础模型的快速发展和AI Agent(智能体)进入规模化应用阶段,被广泛使用的基准测试开始面临一个日益尖锐的问题:真实反映AI的客观能力变得越来越难。
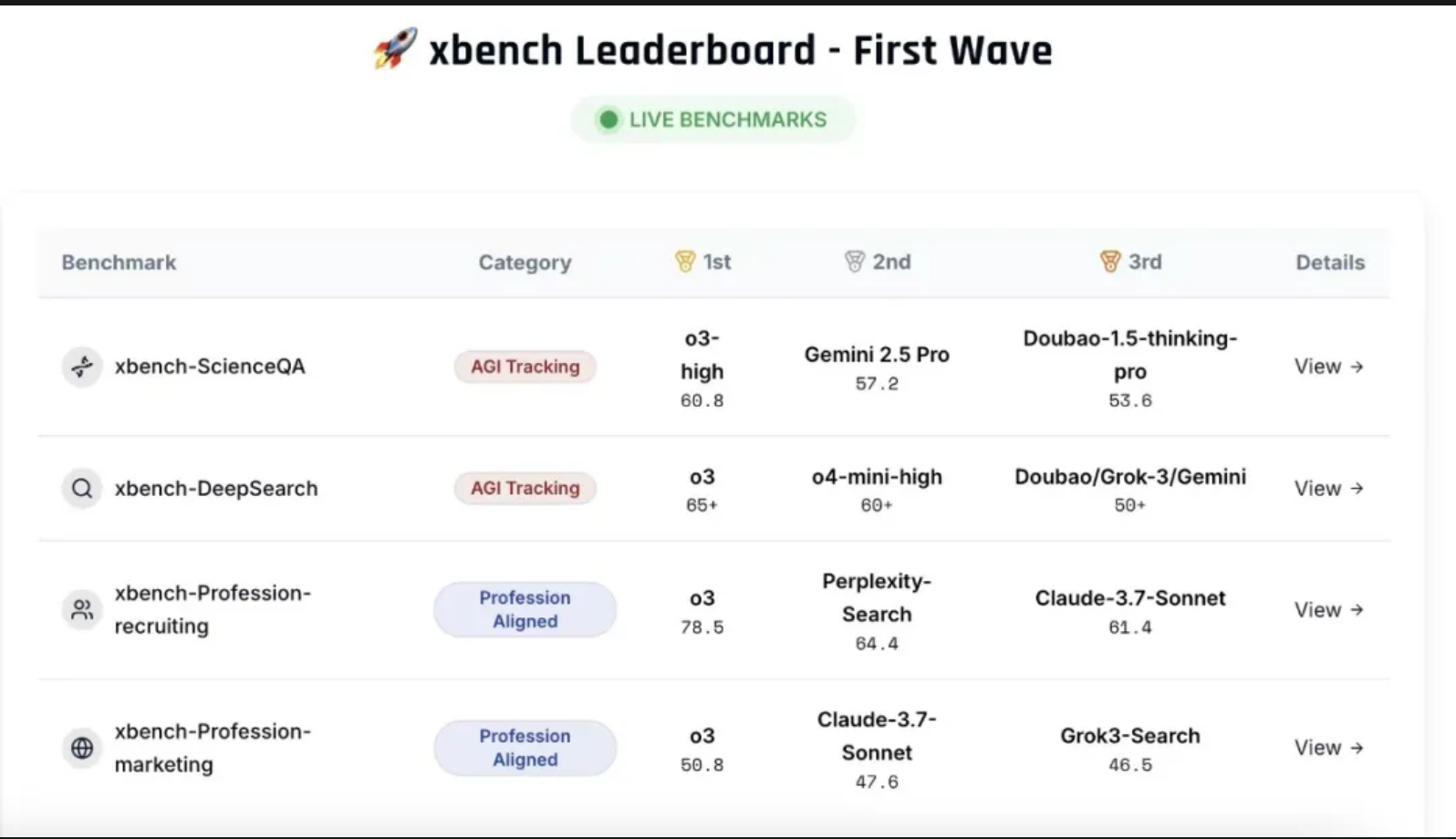
5月26日,红杉中国宣布推出一款全新的AI基准测试工具xbench,由红杉中国发起,联合国内外十余家高校和研究机构的数十位博士研究生,采用双轨评估体系和长青评估机制。
双轨评估体系是指构建多维度测评数据集,同时追踪模型的理论能力上限与Agent的实际落地价值。长青评估机制是指动态的、持续更新的评估方法。此前行业模型进行榜单成绩对比时,会面临“刷榜”质疑。即静态评估集会出现题目泄露问题,模型反复测试可以将分数“刷”上去。
xbench最早是红杉中国在2022年ChatGPT推出后,对AGI进程和主流模型进行的内部月评与汇报工具。在建设和升级“私有题库”的过程中,红杉中国发现主流模型“刷爆”题目的速度越来越快,基准测试的有效时间在急剧缩短。
另外,此次相关机构同期提出垂直领域Agent的评测方法论,并构建了面向招聘与营销领域的垂类Agent评测框架。如今Agent行业正热,包括自主规划、信息收集、推理分析、总结归纳在内的深度搜索能力是AI Agents通向AGI(通用人工智能)的核心能力之一,但这也给评估带来挑战。
AI在长文本处理、多模态、工具使用和推理方面的能力突破催化了AI Agent的爆炸式增长。与聊天机器人相比,Agent不仅可以解决单步问题,还可以交付完整任务,从而提供生产力或商业价值。有价值的AI Agent评估需要与实际任务密切相关,这已成为一种共识。一系列高质量的评估集在工具使用、计算机使用、编码和客户服务等领域出现,推动了Agent在这些各自领域的快速发展。然而,评估结果与 AI 在现实世界中创造经济价值的生产力之间仍然存在差距。为了适应人工智能“下半场”的发展,构建特定领域的Agent评估集至关重要,这需要与专业领域的生产力和商业价值保持一致。
Agent本身的特性也需要考虑,Agent应用产品版本具有生命周期,本身迭代迅速,会不断集成与开发新功能。且Agent接触的外部环境也是动态变化的。即使是相同的题目,如果解题需要使用互联网应用等内容快速更新的工具,在不同时间测试效果不同。因此,测试工具设计指标需要追踪Agent能力的持续增长。
据了解,红杉推出xbench-DeepSearch评测集今年会侧重关注具有思维链的多模态模型能否生成商用水平视频,MCP工具大面积使用是否具有可信度问题,GUI Agents能否有效使用动态更新/未训练的应用三个方向。
(文章来源:第一财经)




